TODO el mundo ha oído ese proverbio que habla de los hijos del zapatero: el zapatero está tan ocupado haciendo zapatos para los demás que sus hijos no tienen sus propios zapatos. Antes de los años 90, muchos de los ingenieros de software fueron los hijos del zapatero. Aunque estos profesionales técnicos construyeron sistemas complejos y productos que automatizan los trabajos de otros, no utilizaron mucha automatización para ellos mismos. En la actualidad, los ingenieros de software han recibido por fin su primer par de zapatos nuevos -la ingeniería del software asistida por computadora (CASE)-.
¿ Que Significa CASE ?
CASE proporciona al ingeniero la posibilidad de automatizar actividades manuales y de mejorar su visión general de la ingeniería. Al igual que las herramientas de ingeniería y de diseño asistidos por computadora que utilizan los ingenieros de otras disciplinas, las herramientas CASE ayudan a garantizar que la calidad se diseñe antes de llegar a construir el producto.
Bloques Básicos Para CASE
La ingeniería del software asistida por computadora puede ser tan sencilla como una única herramienta que preste su apoyo para una única actividad de ingeniería del software, o tan compleja como todo un entorno que abarque «herramientas», una base de datos, personas, hardware, una red, sistemas operativos, estándares, y otros mil componentes más.
¿ Que Significa CASE ?
CASE proporciona al ingeniero la posibilidad de automatizar actividades manuales y de mejorar su visión general de la ingeniería. Al igual que las herramientas de ingeniería y de diseño asistidos por computadora que utilizan los ingenieros de otras disciplinas, las herramientas CASE ayudan a garantizar que la calidad se diseñe antes de llegar a construir el producto.
Bloques Básicos Para CASE
La ingeniería del software asistida por computadora puede ser tan sencilla como una única herramienta que preste su apoyo para una única actividad de ingeniería del software, o tan compleja como todo un entorno que abarque «herramientas», una base de datos, personas, hardware, una red, sistemas operativos, estándares, y otros mil componentes más.

Cada bloque constituye la base del siguiente, con las herramientas situadas en la cima de la pila. Es interesante ver que el fundamento para un CASE efectivo tiene poco que ver con las herramientas de ingeniería del software en si mismas.
Marco de integración: Es un conjunto de programas especializados que permiten a cada herramienta CASE comunicarse con las demás.
Servicios de portabilidad: Este conjunto constituye un puente entre las herramientas CASE, su marco de integración y la arquitectura de entorno. De esta forma permiten que las herramientas CASE y su marco de integración puedan migrar a través de diferentes plataformas de hardware y sistemas operativos sin problemas de adaptación.
Sistema operativo: Gestiona el hardware, la red y las herramientas; mantiene el entorno unido.
Plataforma hardware: Son las estaciones de trabajo individuales interconectadas mediante la red para que los ingenieros del software puedan comunicarse de forma efectiva.
Arquitectura de entorno: Es la base del CASE, en este bloque se construyen los entornos de la ingeniería del software, engloba los sistemas de software y hardware. Además considera los patrones del trabajo humano que se aplican durante el proceso de ingeniería del software
Clasificación de las herramientas case
Las herramientas CASE se pueden clasificar bajo diferentes enfoques:
Marco de integración: Es un conjunto de programas especializados que permiten a cada herramienta CASE comunicarse con las demás.
Servicios de portabilidad: Este conjunto constituye un puente entre las herramientas CASE, su marco de integración y la arquitectura de entorno. De esta forma permiten que las herramientas CASE y su marco de integración puedan migrar a través de diferentes plataformas de hardware y sistemas operativos sin problemas de adaptación.
Sistema operativo: Gestiona el hardware, la red y las herramientas; mantiene el entorno unido.
Plataforma hardware: Son las estaciones de trabajo individuales interconectadas mediante la red para que los ingenieros del software puedan comunicarse de forma efectiva.
Arquitectura de entorno: Es la base del CASE, en este bloque se construyen los entornos de la ingeniería del software, engloba los sistemas de software y hardware. Además considera los patrones del trabajo humano que se aplican durante el proceso de ingeniería del software
Herramientas CASE
Clasificación de las herramientas case
Las herramientas CASE se pueden clasificar bajo diferentes enfoques:
♦ Por su función
♦ Por su papel como instrumentos para el personal técnico o los directivos.
♦ Por la arquitectura del entorno que las soporta (hardware y software)
♦ Origen
Tomando la funcionalidad como criterio principal se creó la siguiente clasificación:
Herramientas de planificación de sistemas de gestión
Proporcionan un "metámodelo" del cual se pueden obtener sistemas de información específicos, mediante la modelización de los requisitos de información estratégica de una organización. El objetivo principal de las herramientas de esta categoría es ayudar a comprender mejor como se mueve la información.
Herramientas de gestión de proyectos
Pueden hacer estimaciones útiles de esfuerzo, coste y duración del proyecto, definir una estructura de partición del trabajo, planificación del mismo y hacer el seguimiento de proyectos de forma continua. Además se pueden utilizar para recoger datos que permitan realizar una estimación de la productividad del desarrollo y la calidad del producto.
Herramientas de planificación de proyectos:
Las herramientas que caen dentro de esta categoría se centran en dos áreas fundamentales: el esfuerzo y coste de un proyecto de software; y la planificación del proyecto.
Herramientas de seguimiento de requisitos:
El objetivo de estas herramientas es de proporcionar un enfoque sistemático para aislar requisitos, comenzando con las especificaciones del cliente. La extracción de requisitos puede ser tan sencilla como encontrar cada ocurrencia del verbo “deber”.

Herramientas de gestión y medida:
Las herramientas de medidas actuales se centran a las características del producto y del proceso.
Las herramientas de medidas actuales se centran a las características del producto y del proceso.
Las herramientas orientadas a la gestión parten de medidas específicas del proyecto que proporcionan una indicación global de la productividad y de la calidad.
Herramientas de soporte
La categoría de herramientas de soporte engloba las herramientas de aplicación y de sistemas que complementan el proceso de ingeniería de software. Estas incluyen herramientas de documentación, herramientas para gestión de redes y software del sistema, herramientas de control de calidad y herramientas de gestión de bases de datos y de configuración del software.
Herramientas de documentación:
Las herramientas de producción de documentación y autoedición se utilizan en casi todos los aspectos de la ingeniería del software y representan una oportunidad muy interesante para todos los que desarrollan software.
Herramientas para software de sistemas:
El CASE es una tecnología de estaciones de trabajo. Por esto, el entorno CASE debe soportar software de redes de comunicación de alta calidad, correo electrónico, boletines electrónicos y otras posibilidades de comunicación.
Herramientas de control de calidad:
La mayoría de las herramientas CASE que se venden como orientadas al control de calidad, son en realidad herramientas de medida que comprueban el código fuente para determinar su compatibilidad con lenguajes estándar. Otras herramientas extraen métricas técnicas como base para medir la calidad del software que se está desarrollando.
Herramientas de bases de datos y de GCS:
El software de gestión de bases de datos sirve como base para el establecimiento de una base de datos CASE (almacén).
Herramientas de análisis y diseño
Las herramientas de análisis y diseño permiten al ingeniero de software crear un modelo del sistema que se va a construir.
Herramientas de AE/DE:
la mayoría de las herramientas de diseño y análisis se basan en el método de análisis y diseño estructurado (AE/DE). El AE/DE es una técnica que permite al ingeniero de software crear progresivamente modelos más complejos de un sistema, comenzando en el nivel de requisitos y concluyendo con un diseño de arquitectura
Herramientas PRO/SIM:
las herramientas de creación de prototipos y de simulación (PRO/SIM) proporcionan al ingeniero de software la capacidad de predecir el comportamiento de un sistema en tiempo real antes de que sea construido.
Herramientas para el diseño y desarrollo de interfaces:
Herramientas de soporte
La categoría de herramientas de soporte engloba las herramientas de aplicación y de sistemas que complementan el proceso de ingeniería de software. Estas incluyen herramientas de documentación, herramientas para gestión de redes y software del sistema, herramientas de control de calidad y herramientas de gestión de bases de datos y de configuración del software.
Herramientas de documentación:
Las herramientas de producción de documentación y autoedición se utilizan en casi todos los aspectos de la ingeniería del software y representan una oportunidad muy interesante para todos los que desarrollan software.
Herramientas para software de sistemas:
El CASE es una tecnología de estaciones de trabajo. Por esto, el entorno CASE debe soportar software de redes de comunicación de alta calidad, correo electrónico, boletines electrónicos y otras posibilidades de comunicación.
Herramientas de control de calidad:
La mayoría de las herramientas CASE que se venden como orientadas al control de calidad, son en realidad herramientas de medida que comprueban el código fuente para determinar su compatibilidad con lenguajes estándar. Otras herramientas extraen métricas técnicas como base para medir la calidad del software que se está desarrollando.
Herramientas de bases de datos y de GCS:
El software de gestión de bases de datos sirve como base para el establecimiento de una base de datos CASE (almacén).
Herramientas de análisis y diseño
Las herramientas de análisis y diseño permiten al ingeniero de software crear un modelo del sistema que se va a construir.
Herramientas de AE/DE:
la mayoría de las herramientas de diseño y análisis se basan en el método de análisis y diseño estructurado (AE/DE). El AE/DE es una técnica que permite al ingeniero de software crear progresivamente modelos más complejos de un sistema, comenzando en el nivel de requisitos y concluyendo con un diseño de arquitectura
Herramientas PRO/SIM:
las herramientas de creación de prototipos y de simulación (PRO/SIM) proporcionan al ingeniero de software la capacidad de predecir el comportamiento de un sistema en tiempo real antes de que sea construido.
Herramientas para el diseño y desarrollo de interfaces:
Las herramientas de diseño y desarrollo de interfaces son, en realidad un conjunto de componentes de software, tales como menús, botones, estructuras de ventanas iconos, mecanismos de visualización, controladores de dispositivos y otros elementos de este tipo.
Herramientas de programación
Engloba los compiladores, los editores y los depuradores que se utilizan con los lenguajes de programación convencionales.
Herramientas de codificación convencionales:
durante casi 30 años las únicas herramientas disponibles para los programadores eran las herramientas convencionales de programación y por esto, cada problema de ingeniería de software era como un problema de programación.
Herramientas de codificación de cuarta generación:
los sistemas de consulta a bases de datos, los generadores de código y los lenguajes de cuarta generación han cambiado la forma de desarrollar sistemas.
Herramientas de programación orientadas a objetos:
Es una de las tecnologías más actuales de la ingeniería de software. Los entornos de programación orientados a objetos suelen estar unidos a lenguajes de programación específicos como: C++, Eiffel, Objetive-C, Smalltalk o Java.
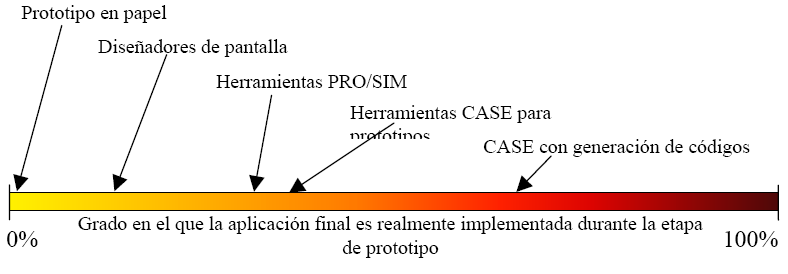
Herramientas de creación de prototipos
La realización de prototipos es un paradigma de la ingeniería de software ampliamente utilizado, todas las herramientas de creación de prototipos se sitúan en algún lugar del espectro de implementación
Herramientas de programación
Engloba los compiladores, los editores y los depuradores que se utilizan con los lenguajes de programación convencionales.
Herramientas de codificación convencionales:
durante casi 30 años las únicas herramientas disponibles para los programadores eran las herramientas convencionales de programación y por esto, cada problema de ingeniería de software era como un problema de programación.
Herramientas de codificación de cuarta generación:
los sistemas de consulta a bases de datos, los generadores de código y los lenguajes de cuarta generación han cambiado la forma de desarrollar sistemas.
Herramientas de programación orientadas a objetos:
Es una de las tecnologías más actuales de la ingeniería de software. Los entornos de programación orientados a objetos suelen estar unidos a lenguajes de programación específicos como: C++, Eiffel, Objetive-C, Smalltalk o Java.
Herramientas de creación de prototipos
La realización de prototipos es un paradigma de la ingeniería de software ampliamente utilizado, todas las herramientas de creación de prototipos se sitúan en algún lugar del espectro de implementación
Herramientas de ingeniería inversa:
utiliza como entrada el programa fuente para extraer y analizar su arquitectura, su estructura de control, el flujo lógico y la estructura y flujo de datos.
Herramientas de reingeniería:
pueden dividirse en dos subcategorías – de reestructuración de código, que aceptan como entrada código fuente si estructurar y realizan el análisis de ingeniería inversa reestructurando el código y agostándolo a los conceptos modernos de programación estructurada; de revisión de datos, que analizan las definiciones de los datos o una base de datos descrita en un lenguaje de programación o en lenguaje de descripción de base de datos, traducen esta descripción a una notación grafica que puede ser analizada por el ingeniero de software.
Ejemplos de herramientas CASE
utiliza como entrada el programa fuente para extraer y analizar su arquitectura, su estructura de control, el flujo lógico y la estructura y flujo de datos.
Herramientas de reingeniería:
pueden dividirse en dos subcategorías – de reestructuración de código, que aceptan como entrada código fuente si estructurar y realizan el análisis de ingeniería inversa reestructurando el código y agostándolo a los conceptos modernos de programación estructurada; de revisión de datos, que analizan las definiciones de los datos o una base de datos descrita en un lenguaje de programación o en lenguaje de descripción de base de datos, traducen esta descripción a una notación grafica que puede ser analizada por el ingeniero de software.
Ejemplos de herramientas CASE

Conclusiones
Las herramientas de ingeniería del software asistida por computadora abarcan todas las actividades del proceso del software y también aquellas actividades generales que se aplican a lo largo de todo el proceso. CASE combina un conjunto de bloques de construcción que comienzan en el nivel del hardware y del software de sistema operativo y finalizan en las herramientas individuales.
La integración entre hombre y computadora se logra mediante estándares de interfaz que se están volviendo cada vez más comunes a lo largo y ancho de toda la industria. Para facilitar la integración de los usuarios con las herramientas, de las herramientas entre sí, de las herramientas con los datos y de los datos con otros datos se diseña una arquitectura de integración



































